
概要
製品概要
AMD の VCK5000 Versal 開発カードは、AMD の 7nm Versal アダプティブ SoC アーキテクチャを採用しており、5G、DC コンピューティング、AI、信号処理、レーダーなどさまざまなアプリケーションに最適です。Vitis™ や Vitis AI、さらに Mipsology Zebra® や Aupera® VMSS などのパートナー ソリューションで包括的にサポートされる VCK5000 はドメイン特化アーキテクチャを採用しているため、C/C++ によるソフトウェア プログラマビリティを備えた使いやすい環境を提供し、ワットあたりの優れた性能を提供します。
AI ベンチマークでワットあたりの計算効率がほぼ 100% を達成し、NVIDIA 社の主力 GPU と比較して 2 倍の費用対効果を提供する VCK5000 は、クラウドおよびエッジでの CNN、RNN、NLP アクセラレーションに最適な開発プラットフォームです。
クラウドで無償評価


AI 推論
AI 推論開発
AI 開発者は、Mipsology Zebra を使用して、TensorFlow や PyTorch で学習したモデルを Versal 上で直接推論したり、FPGA プラットフォームで Aupera VMSS (Video Machine Learning Streaming Server) ソリューションを使用してコンピューター ビジョン アプリケーションをビルド、構成、デプロイできます。
主な特長
VCK5000 を使用する AI 推論開発の主な特徴、パートナー ソリューション、関連記事を紹介します。
.png)
.png)
2 倍の TCO 削減 (主流の GPU と比較)
- ワットあたり性能と価格性能比は 2 倍 (NVIDIA Ampere と比較)
- 90% の計算効率を達成
- 消費電力は 100W 以下 (カード レベル)
.png)
.png)
エンド ツー エンドのビデオ解析スループットは NVIDIA GPU の 2 倍
- H.264 デコードからコンピューター ビジョンまで、最大 10 個の AI モデルでフルパイプラインを実装
- x86 CPU または単一の U30 Alveo カードでビデオ デコードと CV を実行
- FFmpeg/Gstreamer を使用するプラグインのパイプライン設計
ML Heavy: H.264 Decode + Yolov3 + 3x ResNet-18
Video Heavy: H.264 Decode + tinyYolov3 + 3x ResNet-50

使い慣れたフレームワークで作業が簡単
- ハードウェア プログラミングが不要な CPU/GPU ユーザー向けのソフトウェア フロー
- TensorFlow フレームワークを使用してボードで直接推論を実行
- 主要フレームワーク (Pytorch、TensorFlow、TensorFlow 2、Caffe) でサポートされる最先端モデル
パートナー企業のソリューション

Mipsology Zebra AI 推論ソリューション
Mipsology 社 Zebra ソフトウェア
Zebra は操作性に優れた高性能ソフトウェアであり、画像認識 AI アプリケーションのニューラル ネットワークを計算する、AMD が推奨する AI アクセラレータです。
GPU/CPU をシームレスに置き換え、あらゆる画像ベースのニューラル ネットワーク計算を低電力でより高速に実行します。Zebra は、再トレーニングが不要で、ネットワークやアプリケーションの変更も不要です。Zebra はシンプルな Linux コマンドでデプロイされるため、FPGA の専門知識は必要ありません。
VMAccel® クラウドでの Zebra の 5 時間無償デモ版を入手
Aupera インテリジェント ビデオ解析ソリューション
Aupera VMSS (Video Machine Learning Streaming Server) ソリューション
Aupera VMSS は、ビデオ AI 推論アプリケーション向けのソフトウェア フレームワークです。VMSS2.0 では、GUI (グラフィカル ユーザー インターフェイス) 操作で簡単にコンピューター ビジョン パイプラインをビルド、構成、デプロイできるため、コーディングは不要です。デコード、前処理、後処理などの Aupera 社のノード ツールキットを使用して簡単にカスタム パイプラインを構築でき、これらのカスタム ノードの作成はすべて GUI を使用してアップロード、構築、テスト、運用可能です。
Aupera 社の商用ビデオ AI アプリケーションも、このフレームワークをベースに構成して運用および可視化できます。ユーザーは、カスタム パイプラインの結果をビデオ オーバーレイで確認、またはテキスト出力で確認できます。
VMAccel® クラウドでの VMSS 2.0 の 5 時間無償デモ版を入手
AI 推論開発に関する記事




アクセラレーション カードを使用
データセンターでは、監視装置からサーバーの最適化に至るまで、あらゆるタスク管理に AI 技術が導入されています。データセンターで中心的な役割を果たす FPGA ベースのアダプティブ コンピューティングは、多くの場合に複雑な AI ワークロードに対応できる最も効率的かつ費用対効果の高いソリューションであることが実証されています。
VCK5000 開発カードと Vitis AI を組み合わせたベストな使用法を 2021 アダプティブ コンピューティング チャレンジ で紹介しています。



AI エンジン
AI エンジン開発
AI エンジンとプログラマブル ロジックでアルゴリズムの高速化を希望される方には、C/C++ を使用する抽象度の高い AI エンジン API と Vitis アクセラレーション ライブラリを提供しています。Vitis フローでは、C/C++ を使用して開発し、X86 またはエンベデッド プロセッサで実行し、XRT でアクセラレータとの実行時の相互作用を管理します。ハードウェア コンポーネントやカーネルは、C/C++ で開発することも、PL や AI エンジンに対して RTL を使用して開発することも可能です。
主な特長

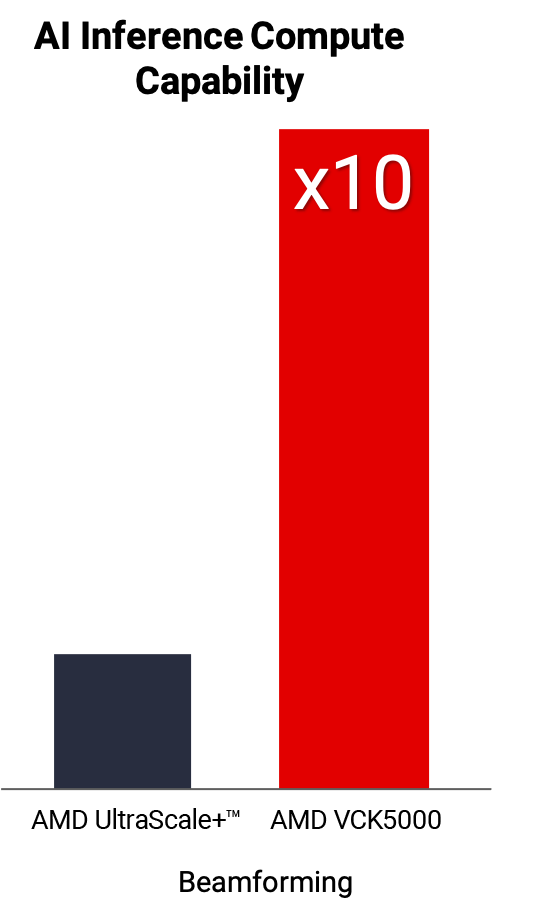
消費電力と性能
- 前世代の AMD UltraScale+™ と比較して最大 10 倍の性能向上が可能で、多様なアプリケーションで消費電力も削減できる
- 業界最先端の計算性能: 最大 145 TOPS (int8); 37 TOPS (int16); 12T FLOPs (fp32)

使い慣れた開発環境
- Vitis 統合ソフトウェア プラットフォームによる使い慣れたソフトウェア開発フロー
- C/C++ を使用する抽象度の高い AI エンジン API と Vitis アクセラレーション ライブラリを利用してアプリケーションを高速化

混合カーネルによる開発
- 混合カーネルで独自のデータ パイプラインをカスタマイズする
- C/C++ で AIE カーネルを開発し、RTL または HLS で PL カーネルを開発して、Vitis でシステム全体を接続する


{kind=link}
{kind=link}
{kind=link}
AI エンジンの開発を始めましょう
Step 1: 購入
量産向けの VCK5000 搭載カードを購入します。
Step 2: セキュア サイトへアクセス
VCK5000 Versal 開発カード セキュア サイトへのアクセスをリクエストします。
Step 3: 開発を始める
VCK5000 Versal 開発カード セキュア サイトの開発開始/インストールに従って始めます。
AI エンジン開発に関する記事




ボードの仕様
| カードの仕様 | VCK5000 | |
|---|---|---|
| デバイス | VC1902 | |
| コンピューティング | アクティブ | パッシブ* |
| INT8 TOPS (ピーク) | 145 | 145 |
| サイズ | ||
| 高さ | フル | フル |
| 長さ | フル | 3/4 |
| 幅 | デュアル スロット | デュアル スロット |
| メモリ | ||
| DDR メモリ容量 | 16 GB | 16 GB |
| DDR 総帯域幅 | 102.4 GB/s | 102.4 GB/s |
| 内部 SRAM の容量 | 23.9 MB | 23.9 MB |
| 内部 SRAM の総帯域幅 | 23.5 TB/s | 23.5 TB/s |
| インターフェイス | ||
| PCI Express | Gen3 x 16 / Gen4 x 8 | Gen3 x 16 / Gen4 x 8 |
| ネットワーク インターフェイス | 2x QSFP28 (100GbE) | 2x QSFP28 (100GbE) |
| ロジック リソース | ||
| ルックアップ テーブル (LUT) | 899,840 | 899,840 |
| 消費電力と熱 | ||
| 最大総消費電力 | 225W | 225W |
| 熱冷却 | アクティブ | パッシブ |
* アクティブ ボードのみを発送します。ハードウェア インストール ガイドに従って VCK5000 からファンを取り外すと、パッシブになります。
資料
デフォルト
デフォルト
タイトル
ドキュメント タイプ
日付